Check out the FAQ,Terms of Service & Disclaimers by clicking the
link. Please register
to be able to post. By viewing this site you are agreeing to our Terms of Service and Acknowledge our Disclaimers.
FluTrackers.com Inc. does not provide medical advice. Information on this web site is collected from various internet resources, and the FluTrackers board of directors makes no warranty to the safety, efficacy, correctness or completeness of the information posted on this site by any author or poster.
The information collated here is for instructional and/or discussion purposes only and is NOT intended to diagnose or treat any disease, illness, or other medical condition. Every individual reader or poster should seek advice from their personal physician/healthcare practitioner before considering or using any interventions that are discussed on this website.
By continuing to access this website you agree to consult your personal physican before using any interventions posted on this website, and you agree to hold harmless FluTrackers.com Inc., the board of directors, the members, and all authors and posters for any effects from use of any medication, supplement, vitamin or other substance, device, intervention, etc. mentioned in posts on this website, or other internet venues referenced in posts on this website.
We are not asking for any donations. Do not donate to any entity who says they are raising funds for us.
Any expression of the second reading frame on PB1 is not good news. As this short protein is novel I don't think anyone knows if it will be biologically active or become fixed. As tyto said we do not want a full PB1-F2 it has always been associated with severe virulence in the past. Seems to have a role along with NS1 in suppressing the role of interferon and can cause inappropriate cytokine expression - see previous link.
So tyto this is the first time this PB1-F2 was found? if so wouldn't this be bad news in itself?
I don't know if this is the first time a working PB1-F2 was found in AH1N1/ 2009. It is however, the first and only sequence currently available in Genbank. It was submitted on 02 Nov 09. I agree with you, it seems like bad news in itself.
This is the first I have heard of an PB1-F2 with a valid stop sequence on this pandemic background. Was in H1N1(1918) and is in HP H5N1.
Where was the sequence collected? Where did you see it do you have the Accession No.?
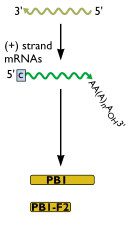
The second RNA segment of the influenza virus genome encodes the PB1 protein - part of the viral RNA polymerase - and, in some strains, a second protein cal ...
Influenza PB1-F2 protein and viral fitness
by Vincent Racaniello on 28 August 2009
The second RNA segment of the influenza virus genome encodes the PB1 protein ? part of the viral RNA polymerase ? and, in some strains, a second protein called PB1-F2. The latter protein is believed to be an important determinant of influenza virus virulence. The absence of a full-length PB1-F2 protein has been suggested as one possible determinant for the low pathogenicity of the 2009 influenza H1N1 pandemic strain. Analysis of the evolutionary history of PB1-F2 suggests that it does not contribute significantly to viral fitness ? the ability of the virus to replicate.
PB1-F2 binds to mitochondria, leading to a release of cytochrome c and induction of apoptosis in CD8 T-cells and alveolar macrophages. The protein increases the severity of primary viral and secondary bacterial infections in mice, and is associated with the high pathogenicity of avian H5N1 and the 1918 H1N1 pandemic virus.
The PB1-F2 protein is not produced in cells infected with the 2009 H1N1 strain because there are three stop codons at nucleotide positions 12, 58, and 88. The PB1 segment of the 2009 H1N1 strain is related to PB1 of H1N2 and H3N2 swine viruses from 1998 and human H3N2 viruses. Curiously, all the relatives of the 2009 H1N1 strain in swine and in humans encode a complete PB1-F2 protein. A truncated PB1-F2 is encoded by the genome of classical swine H1N1 viruses and human H1N1 viruses since 1947. But 96% of the avian influenza virus sequences deposited in NCBI as of 2007 encode the full length version of the protein.
Because the full-length PB1-F2 protein is not encoded in the genome of many influenza viruses, its evolutionary role and contribution to the fitness of the virus is unclear. To answer these questions, the evolution of PB1-F2 was compared with PB1 and two other open reading frames of similar size within the same RNA segment that are not translated into protein.
PB1-F2 is complete in all H1N1 human isolates before 1947, when a stop codon appeared which leads to production of a shorter version of the protein ? 57 amino acids. If the complete protein conferred a functional advantage to the virus, a change in the evolutionary rates of the human H1N1 PB1-F2 proteins should have occurred in 1947. No such change is observed.
Results of sequence analysis reveal that the PB1-F2 open reading frame is as conserved, and maintained as a full-length protein, as other non-coding regions of the same RNA segment and of a randomly generated PB1 segment. These observations, and the fact that PB1-F2 is truncated in many virus isolates, suggest that the evolutionary role of PB1-F2 in animal hosts is minimal. Why the full length protein is produced by some viruses ? and unfortunately leads to higher virulence ? remains a puzzle.
Trifonov, V., Racaniello, V., & Rabadan, R. (2009). The Contribution of the PB1-F2 Protein to the Fitness of Influenza A Viruses and its Recent Evolution in the 2009 Influenza A (H1N1) Pandemic Virus PLoS Currents: Influenza
look at all of these x's there shouldn't be all of those x's that means that they had a hard time sequencing it. this could be lab error or a bad sample
h5n1experts.org is your first and best source for all of the information you’re looking for. From general topics to more of what you would expect to find here, h5n1experts.org has it all. We hope you find what you are searching for!
I haven't yet checked, how the clades correspond.
They have a table with amino-acid mutations
but not nucleotides
They say at least 7 clades so there could be more.
"At least 7 phylogenetically distinct viral clades have disseminated globally and co-circulated in localities that experienced multiple introductions of H1N1pdm. The epidemics in New York and Wisconsin were dominated by two different clades, both phylogenetically distinct from the viruses first identified in California and Mexico, suggesting an important role for founder effects in determining local viral population structures.
snip
The 7 clades vary considerably in size: clade 1 contains 9 isolates, clade 4 has 11 isolates, clade 6 has 13 isolates, clade 2 has 25 isolates, clade 3 has 32 isolates, clade 5 has 77 isolates, and clade 7 has 102 isolates. With the exception of clade 4, which contains isolates collected only from Asia, all clades are geographically dispersed and appear to co-circulate over time and space. As an extreme case in point, 5 different lineages (clades 1, 2, 3, 6, and 7) all co-circulated in New York during week 5 of this study (April 26 – May 2, 2009, Fig. 2). Five clades (clades 2, 3, 4, 5, and 7) co-circulated in Asia during week 8, and clades 2, 3, and 5 co-circulated in Wisconsin during week 6. Although the major epidemics in New York and Wisconsin both were associated with multiple introductions of genetically distinct H1N1pdm, a single clade comprised >80% of virus specimens in each locality: clade 5 in Wisconsin and clade 7 in New York (Fig. 2). Below we describe the evolutionary dynamics of individual clades in further detail.
Clade 1 includes first H1N1pdm isolates that was identified in our study: A/California/04/2009, collected April 1, 2009. A Bayesian MCMC analysis estimates that the Time to the Most Recent Common Ancestor (TMRCA) of clade 1 ranges from February 16 – March 16, 2009 (95% highest probability density (HPD)), confirming that clade 1 was one of the earliest to emerge and that it circulated for ~2 – 6 weeks before initial detection (Fig. 3). However, clade 1 is also the smallest clade in our study (9 isolates) and exhibits only limited geographic dissemination (Fig. 2). Four unique amino acid changes were observed among the majority (7/9) of clade 1 isolates: S224P in the PA and S91P, A200T, and V323I in the HA (H3 numbering system [10]) (Table 1).
Clade 2 also contains isolates from among the earliest known cases of H1N1pdm in Mexico and California (e.g., A/Mexico/4108/2009, collected April 2, 2009). The TMRCA of clade 2 suggests it emerged around the same time as clade 1 (February 14 – March 12, 2009, 95% HPD) and circulated for ~3 – 6 weeks prior to detection (Fig. 3). In contrast to clade 1, clade 2 disseminated widely to Canada, France, Germany, China, and to multiple US states: Indiana, Kansas, Maryland, New York, Washington, and Wisconsin (Fig. 2). Clade 2 is characterized by two amino acid substitutions: M581L (PA) and T373I (NP) (Table 1). Following week 8, no isolates collected globally were members of clade 2 (Fig. 2), but further surveillance is needed to determine whether this clade may still be circulating at low levels.
Clade 3 was detected by surveillance several weeks after clades 1 and 2 (A/Arizona/01/2009, collected April 22, 2009). However, the TMRCA (February 21 – March 19, 2009, 95% HPD) suggests that clade 3 emerged at a similar time as clades 1 and 2, and only was detected later. Clade 3 is the most geographically diverse, containing isolates from Norway, France, England, Germany, Puerto Rico, China, Japan, Canada, Mexico, and the US states of New York, Wisconsin, and Arizona (Fig. 2). Although no amino acid changes have been fixed among all clade 3 isolates, at least 13 different amino acid changes were observed among clusters of isolates contained within this clade (data not shown).
Clade 4 is the only clade in this study that contains isolates from only one region: all 11 isolates are from East Asia. Clade 4 is characterized by fixed amino acid changes in the PB2 (V649I), PB1 (I667T), NP (V100I), and NA (V106I), and NS2 (E63K) (Table 1). Clade 4 was the last to be detected in this study, as the first isolate (A/Korea/01/2009) was not identified until May 2, 2009. However, the TMRCA of clade 4 (March 5 – April 18, 2009, 95% HPD) suggests that clade 4 circulated for ~2 – 7 weeks prior to detection, and likely in non-Asian countries as well (Fig. 3).
Clade 5 is the second largest clade identified here, due primarily to the fact that nearly 88% (71/81) of isolates collected from Wisconsin belong to this clade (Fig. 2). More than 90% (71/77) of isolates in clade 5 were collected from Wisconsin, where the clade was first detected (April 28, 2009) and appears to have proliferated rapidly (Table S1). Clade 5 also was identified several weeks later in Canada, China, and Japan (Fig. 2). Although clade 5 was detected <1 week after clade 3, the TMRCA of clade 5 ranges from March 28 – April 18, 2009 (95% HPD), more than one month later than clades 1, 2, and 3 (Fig. 3). Clade 5 is characterized by amino acid changes in the NP (V100I) and NA (V106I and N248D), relative to basal isolates, but these changes are also observed among clades 6 and 7 (Table 1).
Clade 6 is geographically diverse, given its size in this study (13 isolates) and relatively late TMRCA, ranging from April 4 – April 20, 2009 (95% HPD), which is ~1 – 3 weeks prior to detection (Fig. 3). Following the collection of the first clade 6 isolates on April 28, 2009 in the US, isolates were collected from Canada, China, Italy, and Japan (Fig. 2). In addition to the amino acid changes in the NP and NA that also are observed in clade 5, two unique amino acid substitutions in the HA are present among clade 6 isolates: K(-6)E and Q295H, but neither are epitopes (Table 1).
Clade 7 is the largest identified in this study, representing more than one-third of all isolates (35.2%, 102/290) (Table S1). Almost 83% (67/81) of isolates from New York are members of clade 7. Clade 7 also contains isolates from Canada, China, Japan, Germany, Italy, Luxembourg, Russia, and the US states of California, Maryland, Massachusetts, Ohio, and Wisconsin (Fig. 2). Approximately 40% of the isolates collected from Europe and Asia are members of clade 7 (Fig. 2). Clade 7 is characterized by fixed amino acid changes in the NP (V100I) and NA (V106I and N248D) that are also found in clades 5 and 6, as well as by unique amino acid changes in the HA (S206T) and NS1 (I123V) (Table 1). Clade 7 was first detected April 24, 2009, and the TMRCA of clade 7 ranges from March 28 – April 16, 2009 (95% HPD), suggesting that clade 7 emerged approximately ~1 – 4 weeks prior to the date of first detection in this study and at a similar time as clade 5 (Fig. 3).
Although none of the 12 HA amino acid substitutions that define clades were located in any of the four antigenic subsites of the H1 (13) (Table 1), amino acid changes of potential antigenic importance were observed among 4/290 isolates in this study. In the Cb subsite, S79Y and S79F substitutions were identified in the isolates A/Wisconsin/629-D01521/2009 and A/Wisconsin/629-D01705/2009, respectively. The G159E replacement, located within the Sa subsite, was observed in A/Bayern/62/2009. And A/Wisconsin/629-D0223/2009 experienced the N160T replacement, located within the Sb subsite."
 Tweet
Tweet

Comment